Recent advancements in video super-resolution (VSR) are opening new avenues for enhancing video quality by computational means. Researchers at [Institution or University Name], led by Xiao Chen and Ruyun Jing, have developed a novel method using deformable 3D convolutional group fusion, which promises significant improvements over traditional VSR techniques. This innovative approach addresses the challenges posed by insufficient utilization of temporal and spatial information, leading to higher resolution output from low-resolution video streams.
The crux of the study revolves around the concept of effectively recovering high-resolution (HR) video frames from low-resolution (LR) sequences. With the burgeoning demand for high-quality video across fields such as remote sensing, surveillance, and cinematic production, optimizing VSR techniques has become imperative. The researchers aim to tackle existing shortcomings within popular algorithms, which often fail to leverage the rich dynamics present across frames.
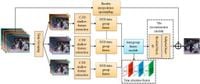
Central to their approach is the implementation of deformable 3D convolution, allowing for nuanced integration of features from video frames, which are grouped based on varying frame rates. By hierarchically managing these groups, the network is able to capture and maintain the spatial and temporal correlations among frames more effectively.
At the heart of this methodology is the novel grouping mechanism, wherein input sequences are divided according to their frame rates. This grouping allows for targeted integration of relevant time information, which is particularly beneficial when restoring missing video details. The deformable 3D convolution serves not only to maintain the integrity of spatial characteristics but also to adapt based on the dynamics observed among the grouped frames.
A significant highlight of the research is the use of a time attention mechanism combined with the group integration module. Such mechanisms are instrumental for informing the network as to which features are most salient across the video frames, aiding the recovery of intricacies often lost during low-resolution capture. The experimental results corroborate the efficacy of this approach; the method achieved a peak signal-to-noise ratio (PSNR) of 27.39 dB and structural similarity index (SSIM) of 0.8266 on the established Vid4 dataset.
When benchmarked against existing VSR models such as VSRnet, VESPCN, and EDVR, this new network demonstrated enhanced performance, achieving improvements of 0.29 dB and 0.12 dB on PSNR compared to established techniques like RBPN and EDVR, respectively. The proposed method not only refined image detail but also expedited the restoration process, proving superior to those models which tend to falter under dynamic conditions.
The experimental setup utilized contemporary hardware, including Intel's Core I5-7500 processor and NVIDIA's RTX-2080 graphics card, underlining the practical applicability of their findings. Utilizing the Pytorch 1.2.0 framework, the researchers were able to achieve optimal processing times and resource efficiency, making the proposed method viable for real-world applications.
Important to note is the basing of their findings on carefully curated video sequences representing diverse scenes, which included settings like urban dynamics and nature, typical of the Vid4 dataset. This comprehensive evaluation not only highlights the versatility of the proposed model but also its adaptability across different video contexts.
Concluding the findings, the authors assert, "The proposed method can significantly improve the performance of image restoration." This statement echoes throughout their research, reinforcing the transformative potential of incorporating advanced computational techniques like deformable 3D convolution within VSR frameworks. Through this innovation, the possibilities for delivering clearer, more detailed video imagery continue to expand.
The exploration and application of temporal attention mechanisms alongside deformable convolutions set this method apart from previous attempts, indicating fruitful directions for future research. Researchers and practitioners alike can look forward to leveraging these advancements to tackle the myriad challenges still presented by video resolution enhancement.