A New Practical Metric for Generalization in Deep Learning Networks
Research indicates that accurately measuring how well deep learning models generalize to unseen data is crucial for advancing AI capabilities.
There is an increasing focus among researchers on developing metrics that effectively quantify the generalization error in deep learning models. This interest arises from both practical implications and theoretical validations that require rigorous benchmarking of model performance on unseen data. A new paper published by a team of researchers introduces a practical generalization metric intended to benchmark various deep networks while proposing a novel testbed to verify theoretical estimations regarding these models.
The study highlights that the generalization capacity of deep networks, especially in classification tasks, is dependent not only on classification accuracy but also significantly on the diversity of the unseen data. "A deep network’s generalization capacity in classification tasks is contingent upon both classification accuracy and the diversity of unseen data," wrote the authors of the article. This dual dependency illuminates a critical aspect of deep learning assessment that previous metrics may not have adequately addressed.
The research establishes a system capable of quantifying deep learning models' accuracy and the diversity of input data, enabling a more intuitive and quantitative evaluation method. It emphasizes that most existing generative estimation methods do not correlate well with practical measurements obtained through their testbed. "Most of the available generalization estimations do not correlate with the practical measurements obtained using our testbed," wrote the authors of the article.
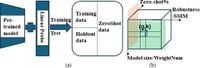
To effectively evaluate how these deep networks capture essential features, the proposed benchmark testbed employs a structure called the linear probe CLIP. This benchmark delineates a comprehensive evaluation strategy where the data is divided into training sets and holdout data. Through this, the pretrained models undergo fine-tuning on training datasets before being tested on the holdout datasets.
Measured data involves gathering ErrorRate and Kappa values across three distinct dimensions: model size—representing the number of weights, robustness defined by the addition of noise, and zero-shot capacity which relies on evaluating unseen classes. “The benchmark testbed utilizes the linear probe CLIP structure to evaluate how effectively a deep learning model captures essential features within its hidden layers,” noted the authors of the article.
The findings indicate that model performance directly correlates with its size, the training data size, and the computational resources allocated during training. Insights gathered from the study reflect that metrics like ErrorRate provide an insightful look into the error distribution of individual classes which were evaluated using statistical measures such as Kappa statistics. A model exhibiting strong generalization capacity must adapt well to highly diverse data while achieving low ErrorRates.
Furthermore, experiments were conducted using CIFAR-100 and ImageNet datasets to validate the effectiveness of the proposed metric. Each dataset was segmented to engage with a zero-shot scenario effectively. The researchers selected 50 classes from CIFAR-100 for training and utilized the remaining 50 classes for tests. Similarly, 100 classes were randomly selected from the ImageNet dataset, maintaining that half are committed to training while the rest are held for testing.
This methodological set-up resulted in critical findings which suggest that both CLIP and EfficientNet models were assessed during these experiments, illustrating varying performances in generalization across dimensions. Their benchmark revealed which model performed better under specific conditions and highlighted disparities in performance pertaining significantly to data characteristics and noise robustness.
The results underscored that the generalization and diversity bounds on ImageNet were significantly lower than on CIFAR-100. This brings to light the distinctions in effectiveness that varied image sizes impose on AI training and subsequent efficiency on unseen data contexts.
Additionally, the research examined existing theoretical generalization estimations against practical measures but noted significant misalignments. Figures indicated discrepancies where many expected generalization bounds failed to manifest accurately within practical trials; hence, raising concerns over the reliability of current theoretical estimations.
The study also proposes future work to enhance the benchmarking framework, which currently encompasses key aspects, including model size, robustness, and zero-shot capacities. Integration of explainable AI tools and additional architectural considerations aims to extend the scope of this research. To encourage industry engagement, the authors announced plans to create a public GitHub repository for deep network benchmarking, inviting community contributions and insights.
Ultimately, the practical generalization metric established through this study provides foundational benchmarking for deep learning networks. It enables researchers to assess how effectively their models perform in practical environments while recommending investigation into more extensive datasets and varied architectures. The ongoing challenge remains the necessity to develop reliable methodologies capable of genuinely reflective measures of generalization capacity across complex AI systems.
In conclusion, as deep learning technologies evolve, establishing robust and reliable metrics will be crucial in ensuring these systems perform effectively in real-world applications.