On March 29, 2025, Tencent AI Researchers unveiled Hunyuan-T1, a groundbreaking ultra-large language model that promises to reshape the landscape of natural language processing (NLP). This innovative model integrates a novel Mamba architecture with advanced reinforcement learning and curriculum strategies, specifically designed to tackle the challenges associated with processing lengthy and complex texts.
Hunyuan-T1 is built on the TurboS fast-thinking base, which optimizes the processing of long textual sequences while minimizing computational overhead. This architecture allows the model to effectively capture extended context and manage long-distance dependencies, a crucial capability for tasks that demand deep, coherent reasoning. As AI continues to evolve, the ability to maintain context over longer texts has become increasingly important, as traditional models often suffer from context loss and inefficient handling of long-range dependencies.
A standout feature of Hunyuan-T1 is its heavy reliance on reinforcement learning (RL) during the post-training phase. Tencent dedicated an impressive 96.7% of its computing power to this approach, enabling the model to iteratively refine its reasoning abilities. Techniques such as data replay, periodic policy resetting, and self-rewarding feedback loops help to improve output quality, ensuring the model’s responses are not only detailed and efficient but also closely aligned with human expectations.
To further enhance reasoning proficiency, Tencent employed a curriculum learning strategy, which gradually increases the difficulty of training data while simultaneously expanding the model’s context length. This strategy allows Hunyuan-T1 to efficiently transition from solving basic mathematical problems to tackling complex scientific and logical challenges.
Efficiency is a cornerstone of Hunyuan-T1’s design. The TurboS base’s capability to capture long-text information prevents context loss, a common issue in many language models, and doubles the decoding speed compared to similar systems. This breakthrough means users benefit from faster, higher-quality responses without compromising performance.
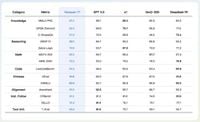
The model has achieved impressive scores on multiple benchmarks, showcasing its versatility and ability to handle high-stakes, professional-grade tasks across various fields. Hunyuan-T1 scored 87.2 on MMLU-PRO, which tests various subjects including humanities, social sciences, and STEM fields; 69.3 on GPQA-diamond, a challenging evaluation featuring doctoral-level scientific problems; 64.9 on LiveCodeBench for coding tasks; and a remarkable 96.2 on the MATH-500 benchmark for mathematical reasoning.
These results underscore Hunyuan-T1’s capacity to excel in diverse applications, making it a valuable tool for researchers and professionals alike. Beyond quantitative metrics, Hunyuan-T1 is designed to deliver outputs with human-like understanding and creativity. During its RL phase, the model underwent a comprehensive alignment process that combined self-rewarding feedback with external reward models. This dual approach ensures that its responses are accurate and exhibit rich details and a natural flow.
The introduction of Hunyuan-T1 marks a significant milestone in the field of artificial intelligence. Asif Razzaq, the CEO of Marktechpost Media Inc., highlighted the model's potential, stating that it represents a leap forward in AI's ability to understand and process human language. Razzaq, a visionary entrepreneur and engineer, is committed to harnessing the potential of artificial intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience.
As the AI community eagerly anticipates the impact of Hunyuan-T1, it is essential to recognize the challenges that lie ahead. While this model offers remarkable advancements, the need for continuous improvement in AI language processing remains. The integration of reinforcement learning and curriculum strategies in Hunyuan-T1 provides a promising framework for future developments in the field.
In conclusion, Tencent’s Hunyuan-T1 combines an ultra-large-scale, Mamba-powered architecture with state-of-the-art reinforcement learning and curriculum strategies. Its high performance, enhanced reasoning, and exceptional efficiency position it as a leading contender in the evolving world of language models. As the technology continues to advance, the potential applications for Hunyuan-T1 are vast, paving the way for a new era of intelligent communication and understanding.
For those interested in exploring the capabilities of Hunyuan-T1 further, additional resources and updates can be found on the Details, Hugging Face, and GitHub pages. The research community is encouraged to engage with this groundbreaking model, as it holds the promise of transforming how we interact with technology and each other.