On April 14, 2025, OpenAI unveiled a new suite of language models aimed at enhancing developer capabilities in coding and programming tasks. The leading model in this release, GPT-4.1, is touted as significantly better than its predecessor in terms of coding efficiency and accuracy. Alongside GPT-4.1, OpenAI also introduced two additional models, GPT-4.1 mini and GPT-4.1 nano, designed to cater to different needs and budgets.
All three models have the impressive ability to process prompts containing up to 1 million tokens, making them suitable for analyzing substantial datasets, such as entire GitHub repositories. This capability is crucial for developers who often send multiple prompts that reference previous inputs. OpenAI claims that GPT-4.1 can identify information from past messages in a conversation 10.5% better than the previous version, enhancing its utility for complex programming tasks.
One of the most notable improvements in GPT-4.1 is its output efficiency. Traditionally, when developers requested changes to a code file, earlier models would return not only the requested modifications but also the unchanged portions of the original file. This practice inflated costs, as OpenAI charges based on the volume of output. To address this, the engineers at OpenAI configured GPT-4.1 to output only the modified lines of code, significantly reducing unnecessary data processing.
In a move to further reduce costs for developers, OpenAI also increased its caching discount from 50% to 75%. This means that users can save even more when they cache answers to frequently entered prompts, making the overall experience more economical.
OpenAI’s GPT-4.1 mini model, while less advanced than GPT-4.1, still offers competitive performance. It reduces latency by nearly half and cuts costs by an impressive 83%. As OpenAI detailed in their blog post, “It matches or exceeds GPT-4o in intelligence evaluations while reducing latency by nearly half and reducing cost by 83%.”
The third model, GPT-4.1 nano, is designed for simpler tasks such as sorting documents or powering code autocomplete features. It not only costs less but also promises lower latency compared to its more advanced counterparts. OpenAI has improved its inference stack to reduce the time to the first token, claiming that the p95 latency to the first token for GPT-4.1 is approximately 15 seconds with 128,000 tokens of context and up to half a minute for 1 million tokens.
Interestingly, OpenAI has decided not to integrate GPT-4.1 into its ChatGPT service. Instead, the company plans to refine the coding and instruction-following capabilities of the earlier GPT-4o model that powers the chatbot, indicating a strategic focus on enhancing existing models rather than introducing the latest version into this particular application.
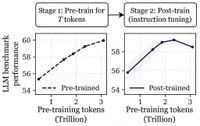
Meanwhile, a study conducted by researchers from prestigious institutions including Carnegie Mellon University, Stanford University, Harvard University, and Princeton University has revealed potential pitfalls in the training of large language models. Their findings suggest that over-training these models may lead to difficulties in fine-tuning them effectively.
The research team compared the performance of the OLMo-1B model when trained with 2.3 trillion tokens versus 3 trillion tokens. Surprisingly, they discovered that the model trained on 3 trillion tokens performed up to 3% worse on benchmarks such as ARC and AlpacaEval. This phenomenon, which the researchers have termed "catastrophic overtraining," highlights a point of diminishing returns in model training.
According to the researchers, as the number of tokens increases, the model becomes more fragile, making it harder to fine-tune effectively. They identified what they call an "inflection point," beyond which additional training can actually reduce the model's stability and performance. To further investigate their theory, the team added Gaussian noise to some models, confirming that this led to similar performance degradation.
In the realm of AI research, another exciting development is the exploration of whether AI systems can benefit from reasoning independently of language. Recent studies have introduced deep neural networks that allow language models to continue thinking in mathematical spaces before producing any text.
One such model, developed by Shibo Hao and his team at Meta, is named Coconut. This model, based on GPT-2, is designed to reason primarily in latent space, allowing it to process information without constantly converting it into language. In tests, Coconut demonstrated remarkable efficiency, achieving 98.8% accuracy in logical reasoning while using only about one-tenth the tokens of its standard counterpart.
However, Coconut faced challenges with elementary math problems, achieving only 34% accuracy compared to 43% for the GPT-2 model. Hao suspects that if Coconut had been trained from the outset to utilize latent space reasoning, its performance might have improved significantly.
In a parallel effort, Tom Goldstein's team at the University of Maryland developed a recurrent model that allows for increased flexibility in processing information. By effectively allowing the model to reuse layers, they created a system that can adaptively increase its computational depth based on the complexity of the task. This model outperformed OLMo-7B, achieving 28% accuracy on elementary math problems compared to OLMo's 4%.
Despite these advancements, experts caution that incorporating latent reasoning into mainstream models may take time. Current industry leaders like OpenAI and Anthropic are heavily invested in their existing architectures, which may hinder the adoption of these innovative techniques.
As researchers continue to explore the frontiers of AI and language models, the potential for fundamentally changing how these systems reason and process information remains an exciting prospect. The journey toward more efficient and intelligent AI systems is just beginning, and the implications for various fields are profound.