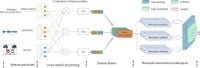
The growing field of multimodal sentiment analysis is taking a new leap forward with the introduction of a novel model known as the Multimodal GRU (MulG). This state-of-the-art model is designed to effectively combine and analyze textual, audio, and visual signals to better understand human emotions. The driving force behind MulG is a unique cross-modal attention mechanism that aligns and synchronizes these disparate signals, ultimately enabling a more cohesive understanding of sentiment.
In recent years, understanding human emotions has become a central focus of affective computing, with applications ranging from social media analytics to mental health diagnostics. Traditionally, approaches to sentiment analysis often relied on just one modality, which could lead to incomplete interpretations of emotional signals. Recognizing this limitation, researchers have developed multimodal sentiment analysis frameworks to integrate vital information from various input sources.
However, previous methods have struggled with their own limitations: early fusion techniques proved computationally demanding, while late fusion approaches often overlooked key interdependencies among modalities. Furthermore, while transformer models have shown promise in modeling complex relationships through self-attention, their heavy computational demands render them less practical for real-time applications. MulG aims to overcome these challenges with its novel design.
The MulG model employs gated recurrent unit (GRU) layers, which are particularly effective in handling sequential data with efficiency and accuracy. By incorporating these layers, MulG not only captures temporal dependencies within data but does so without significantly increasing computational complexity. This makes the model a practical option for sentiment analysis in various real-world scenarios.
In an extensive evaluation, MulG demonstrated exceptional performance across several benchmark datasets including CMU-MOSI, CMU-MOSEI, and IEMOCAP. Specifically, it achieved a robust 82.2% accuracy on the CMU-MOSI 7-class task, 82.1% on CMU-MOSEI, and an impressive 90.6% for happy emotion classification in IEMOCAP.
Sophisticated to its core, MulG implements a directed pairwise cross-modal attention mechanism that intelligently aligns asynchronous features across multiple modalities. This ability allows the model to capture complex interactions that traditional models may overlook, making it capable of delivering insightful analyses for applications such as user-generated content and improving human-computer interaction.
The design of the model also allows for multiple modalities to be processed effectively, setting it apart from earlier approaches that fused modalities either too early or too late in the analysis process. By bringing all relevant data streams into synchronization, MulG enhances understanding and capability in complex emotional recognition tasks.
Ablation studies conducted on the MulG model showcased the significant contributions made by each component to the overall performance. For instance, removing any one modality drastically reduced accuracy, underscoring the critical role of multimodal integration.
At its heart, the development of MulG responds to the pressing need for scalable and effective models capable of performative sentiment analysis under variable conditions. As data sources proliferate, from social media to casual dialogue, the techniques adopted by the MulG model can improve how real-world emotional data is understood and addressed.
The implications are substantial: as researchers continue refining this groundbreaking model, its potential applications could reshape user experience across digital platforms. Whether for enhancing social media sentiments, optimizing mental health diagnostics, or bettering human-computer interactions, MulG promises to deliver necessary advancements in understanding and interpreting human emotion.
To access the MulG code and datasets for further research, visit the resources provided by the research team at https://github.com/bitbitlemon/Multimodal-GRU and datasets like CMU-MOSI and IEMOCAP.