In the rapidly evolving field of natural language processing (NLP), researchers have discovered significant vulnerabilities in models due to adversarial attacks, prompting the need for more robust solutions. A recent study introduces a groundbreaking method known as QEAttack, which enhances the efficiency of adversarial text generation by minimizing the number of queries required during the attack process while maintaining high levels of success.
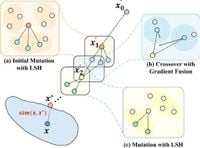
Adversarial attacks, which involve manipulating inputs to deceive machine learning models, have become a pressing challenge as reliance on these systems grows. Traditional methods often require extensive queries to correctly generate adversarial texts, creating inefficiencies in real-world applications. Recognizing this urgent need, researchers have developed QEAttack, a novel approach that integrates genetic algorithms with dual-gradient fusion and locality sensitive hashing techniques to create persuasive and semantically equivalent adversarial texts.
The methodology seeks to address the shortcomings of current adversarial attack strategies using a hard-label framework. By leveraging the final predicted label output from victim models, QEAttack significantly reduces the overall query counts necessary for effective adversarial text generation. This innovation stems from a comprehensive understanding of the dynamics involved in adversarial attacks, where even minor text modifications can lead to substantial model misclassifications.
The researchers conducted extensive experiments across five benchmark datasets, including AG's News and the IMDb dataset, employing different neural network architectures such as BERT and WordLSTM. Results of these experiments reveal that QEAttack achieves an impressive average attack success rate of 98.10% while the semantic similarity of the generated adversarial texts stands at 92.28%.
One of the standout features of QEAttack is its ability to generate adversarial texts with a remarkably low perturbation rate, averaging just 8.19%. This efficiency enhances the imperceptibility of the changes made to the original texts while yielding high-quality outputs. Furthermore, the study reports an average ROUGE score of 91.01%, indicating that the generated texts retain substantial semantic coherence with the originals.
"QEAttack effectively reduces the required query counts during the adversarial text generation process, while preserving attack efficacy, imperceptibility, and quality of generated adversarial texts," the authors of the study noted. This advancement could significantly reshape how researchers and industries approach the design of NLP models, striving for increased robustness against adversarial threats.
Moreover, the work highlights the dual-gradient fusion strategy — inspired by the Adam optimization method — which merges gradient information from multiple candidates to enhance the generation process. In addition, the use of locality sensitive hashing to categorize semantically similar sentences ensures that only the most relevant queries are processed, vastly improving efficiency.
The implications of this research extend beyond merely crafting adversarial examples. It lays the groundwork for more sophisticated security measures within NLP systems, essentially performing a dual role: both exposing weaknesses in existing models and offering insights into fortifying these systems against potential threats.
Although QEAttack presents promising results, the research acknowledges certain limitations. Specifically, the method may still require a considerable number of queries for generating adversarial examples when dealing with longer texts. In light of this, the authors express intent to refine the QEAttack method further to enhance its efficiency while expanding its applicability to more complex language processing tasks.
In conclusion, the development of QEAttack represents a substantial advancement in adversarial text generation, addressing significant inefficiencies previously associated with such techniques. As researchers continue to explore and innovate in the world of NLP, the findings presented in this study are poised to influence future methodologies aimed at improving model robustness. Future implementations and refining of QEAttack could pave the way towards creating more secure and reliable NLP applications across various sectors.