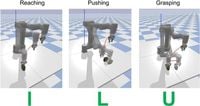
One of the significant challenges faced by robotics today is effectively learning new skills from limited data. A recent advancement, published by Binzhao Xu, Muhayy Ud Din, and Irfan Hussain on March 17, 2025, presents a novel framework integrating conditional variational autoencoder (cVAE) with dynamic motion primitives (DMP) to boost multitask imitation learning capabilities. This method allows robots to accomplish complex tasks such as pushing, reaching, and grasping using just one demonstration for each task, marking a remarkable step forward for robotic manipulation.
The ability of robots to learn through demonstration is pivotal for their deployment across various domains, including manufacturing, healthcare, and domestic environments. Traditional approaches, particularly DMP, have been successful but often require extensive datasets to develop precise, adaptable movements. DMP frameworks model desired movements as smooth trajectories directed by attractors but typically focus on single tasks, which limits their effectiveness when faced with multiple task demands.
Recognizing these constraints, the authors proposed combining the strengths of DMP and cVAE, creating a system where deep neural networks generate conditioned torque instead of directly producing trajectories. This innovative approach decouples the task from the typical reliance on numerous demonstrations by allowing the robot to adapt to new conditions swiftly. The method can generate new trajectories to reach designated positions with high precision—successfully completing tasks such as reaching with 100% accuracy and achieving 93.33% success rates for pushing and grasping tasks.
Theoretical insights for this framework involve learning from various task demonstrations. Researchers began by noting the unique shapes trajectories take during different tasks; for example, reaching manifests as straight lines, whereas pushing tasks display L-shaped trajectories. The authors trained their model using normalized demonstrations for distinct tasks, leading to oscillations of precise movement through dynamic adjustment of torque to align with task parameters.
The proposed technique is particularly adept at fine-tuning trajectories quickly. The authors note, "The proposed method can adjust the trajectories to new task conditions within 0.5 seconds, and the decoder and scaler parameters can be fine-tuned within 1 second." Such rapid adaptability highlights the practical utility of the model, effectively positioning it as superior to existing methods requiring significantly more training data. This was demonstrated through systematic evaluations where the authors engaged the system on multiple robotic manipulation tasks.
Validation was carried out using the UR10 robotic manipulator, showcasing how the new method retained efficiency and performance even with untrained task statuses. For example, slight modifications to endpoint constraints and via points present opportunities for the model to be quickly retrained, leading to excellent success rates across various operations. Notable is the reported final state error, which fell below 0.008 after adjustments, along with consistently low via-point errors, demonstrating its ability to adapt trajectories without losing movement integrity.
Current findings pinpoint success not only at the demonstration level but also via advanced generalization to previously unencountered movements and trajectories. A significant point made by the authors states, "Achieving 100% success rate in the reaching task and 93.33% success rate in pushing and grasping tasks with only one demonstration provided for each task is noteworthy," emphasizing the framework's efficiency and effectiveness.
Going forward, the versatility of the cVAE-DMP method introduces immense possibilities for robotic applications across multiple domains. While the framework demonstrated potent abilities, it also acknowledged areas for improvement, especially surrounding the tasks needing user-defined parameters relating to the desired trajectories. Further development may involve the integration of large language models (LLMs) to automate definitions, allowing for high-level task management and potentially refining the process of defining via points and end states based on contextual comprehension.
Overall, the conclusive findings reveal how the synergy of DMP with cVAE opens pathways to enhanced robotic autonomy through groundbreaking learning strategies, paving the way for future research and applications across intelligent robotics.