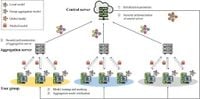
In a rapidly digitalizing world, federated learning (FL) has emerged as a distributed machine learning approach, effectively mitigating data silos and enhancing data privacy. As organizations and individuals generate vast troves of data through an ever-growing array of devices, the risk associated with centralized data management becomes a critical concern. A new study, detailed in this report, introduces a groundbreaking secure aggregation scheme named Group Verifiable Secure Aggregation (GVSA), which addresses key vulnerabilities while ensuring efficient performance.
Federated learning operates on the premise that data privacy is paramount. In essence, it allows multiple parties to collaboratively train machine learning models without exposing their raw data. While this innovation addresses privacy concerns, it does not entirely eliminate the risk of privacy leaks through intermediate updates, such as gradients or model parameters. Moreover, the centralized aggregation server—which combines the models from different users—poses a potential single point of failure in the system, making it susceptible to manipulation and cyberattacks.
To combat these challenges, researchers developed GVSA, which leverages secret sharing techniques and lightweight validation processes to enhance security without incurring significant computational overhead. The method utilizes a dual aggregation approach and incorporates verification tags to authenticate the accuracy of the aggregation results, fundamentally improving the resilience of federated learning in resource-limited environments.
As part of the study, the authors implemented GVSA and compared its performance against existing state-of-the-art secure aggregation techniques. The results demonstrate that GVSA not only maintains high data security but is also computationally efficient. It was found that GVSA requires approximately 7% more processing power than traditional methods like Federated Averaging (FedAvg), while achieving a remarkable 2.3-times speed increase over other secure aggregation protocols with similar security levels. This balance between computational efficiency and privacy preservation makes GVSA a promising solution for practical applications in federated learning.
The development of GVSA stems from foundational challenges faced in federated learning. For instance, many existing privacy-preserving methods incur large computational costs, making them impractical for use in real-world scenarios with limited computational resources. These methods often utilize techniques like homomorphic encryption or differential privacy, which, although effective in protecting data, can lead to significant decreases in model performance due to computational demands.
GVSA effectively reduces these burdens by employing a grouping strategy that minimizes the computational load on users and the server. By separating users into groups, each individual performs fewer operations, thus streamlining the entire secure aggregation process and bolstering functionality.
As the demand for responsible data management practices grows, GVSA represents a leap forward in model privacy and training efficiency. Future research will look to further enhance the scheme's capabilities by integrating advanced technologies, such as blockchain, and developing robust solutions to shore up against potential side-channel threats that might arise in practical deployments.
In summary, GVSA marks a significant advancement in federated learning technology, presenting an efficient and effective approach to secure model aggregation without sacrificing privacy or performance in resource-constrained environments. This innovation illustrates the power of collaborative approaches to machine learning while addressing growing concerns over data privacy and security.