On September 13, 2025, two significant articles—one from hackernoon.com and another from Quantum Zeitgeist—cast a spotlight on the rapidly evolving world of generative artificial intelligence. The conversation, once dominated by the power and scale of large language models (LLMs), is now shifting toward smaller, more efficient models and, perhaps more importantly, new ways to make these systems smarter and more reliable. At the heart of this transformation is a breakthrough approach in reinforcement learning called Curiosity-Driven Exploration, which promises to tackle some of the most stubborn problems in AI reasoning and creativity.
For years, the AI community has marveled at the capabilities of massive language models—systems trained on vast swaths of the internet, capable of generating text, solving problems, and even engaging in basic conversation. But as hackernoon.com reported in its September 13 article, there’s a growing sense that bigger isn’t always better. The trend is now toward smaller language models, which are easier to train, more energy-efficient, and potentially more adaptable to specific tasks. This shift raises a fundamental question: Can these smaller models keep up with their heavyweight predecessors, especially when it comes to complex reasoning?
Enter the research team of Runpeng Dai, Linfeng Song, and Haolin Liu, whose work was highlighted by Quantum Zeitgeist on the same day. Their study introduces a fresh perspective on how to train language models—large or small—to reason more effectively. The core of their innovation is a reinforcement learning framework called Curiosity-Driven Exploration. What does that mean, exactly? In simple terms, it’s about making AI curious—encouraging models to seek out new information, explore unfamiliar territory, and avoid falling into ruts of repetitive or predictable output.
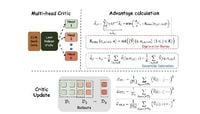
Traditional reinforcement learning methods, which have powered everything from game-playing AIs to robotic arms, often struggle with poor exploration. Models can get stuck doing what they already know works, missing out on better solutions that require a bit of risk-taking or creative thinking. According to Quantum Zeitgeist, the new Curiosity-Driven Exploration framework formalizes curiosity by generating signals from both the model’s response generation (the “actor”) and its evaluation of outcomes (the “critic”). These signals are then used to create an exploration bonus—a kind of internal reward—that nudges the model to try new approaches.
How does this work in practice? The researchers measure the actor’s curiosity by looking at the perplexity over generated responses—a statistical measure of how surprising or uncertain the model finds its own output. Meanwhile, the critic’s curiosity is gauged by the variance in value estimates from a multi-head architecture, which means the model uses several different perspectives to judge the same situation. The more disagreement among these perspectives, the more the model is encouraged to explore further.
This isn’t just a clever theoretical trick. The team’s experiments show real-world results: incorporating these curiosity signals as exploration bonuses leads to approximately a three-point improvement over standard methods on challenging mathematical reasoning benchmarks, such as the AIME tests. That’s not just a statistical blip—it’s a meaningful step forward in the quest to make language models better thinkers, not just better parrots.
But the research doesn’t stop at performance metrics. The team also uncovered a critical calibration issue within standard reinforcement learning approaches—a phenomenon they call “calibration collapse.” This occurs when the reward system in the model focuses too much on getting the final answer right, at the expense of the reasoning steps that lead there. The result? Models that sometimes hallucinate or make confident mistakes, because they’re not incentivized to check their work along the way. By introducing alternative reward structures—such as perplexity-based bonuses—the researchers show that it’s possible to keep models both accurate and honest in their reasoning.
The implications of this work are far-reaching. As Quantum Zeitgeist explains, the Curiosity-Driven Exploration framework doesn’t just make models smarter; it makes them more robust and reliable. By addressing the twin problems of premature convergence (where a model settles too quickly on a single way of doing things) and loss of diversity (where it stops considering alternative solutions), this approach opens the door to AI systems that can adapt, learn, and even surprise us in constructive ways.
This research also builds on established concepts in machine learning and statistics. The team’s approach to estimating the exploration bonus is grounded in linear Markov Decision Processes, a mathematical framework that simplifies the learning problem by representing rewards and transitions linearly. They use bootstrapping—a resampling technique familiar to statisticians—and combine it with a multi-head critic, which employs multiple value estimators to reduce uncertainty. This careful blending of old and new ideas results in a method that not only works in practice but comes with theoretical guarantees: under certain conditions, the exploration bonus estimate converges to the true value, making the system both effective and reliable.
For those following the broader arc of AI development, this shift from sheer scale to smarter exploration is a welcome change. As hackernoon.com noted, the move toward smaller language models is driven by practical concerns—energy use, data privacy, and the need for specialized tools that don’t require a supercomputer to run. But the real magic happens when these models are paired with training methods that make them more than just miniaturized versions of their larger cousins. Curiosity-Driven Exploration is one such method, offering a lightweight yet powerful way to boost reasoning without ballooning computational costs.
Of course, challenges remain. The calibration collapse identified by the researchers is just one example of the subtle pitfalls that can trip up even the most advanced AI systems. But by shining a light on these issues—and providing concrete solutions—the team has helped chart a path forward for the next generation of language models.
As the field of generative AI continues to evolve, the lessons from this research are clear: bigger isn’t always better, and curiosity might just be the secret ingredient that keeps artificial intelligence moving forward, one thoughtful step at a time.