YouTube has emerged as a primary platform for health-related information, yet many videos contain inaccurate or biased content. A recent study explores the potential of Large Language Models (LLMs) to evaluate the quality of medical videos on YouTube, addressing the challenges posed by inconsistent content quality.
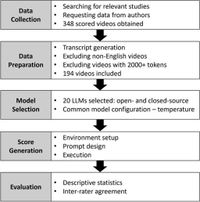
Researchers collected a dataset of health-related videos that had previously been assessed by experts using the DISCERN instrument, a standardized tool for evaluating health information quality. Twenty LLMs were prompted to rate these videos, revealing a range of inter-rater agreements with expert evaluations, from as low as -1.10 to as high as 0.82. Notably, all models tended to assign higher scores than human experts, raising questions about the reliability of both AI and expert ratings in the context of medical content.
The study highlights the pressing need for effective evaluation methodologies in a landscape where health-related content is proliferating rapidly. With the sheer volume of daily uploads to YouTube, expert reviews become impractical, yet the accuracy of information shared online is crucial for public health. The inconsistent nature of medical content on this platform, often created by both experts and non-experts, complicates assessments of credibility and unbiased delivery of information.
The research utilized video transcripts, some of which were directly provided by content creators while others were generated using advanced transcription tools. After applying the DISCERN criteria to these videos, the researchers initiated a series of tests employing both zero-shot and guided-scoring prompts designed to improve model performance. Results indicated that providing specific scoring guidelines enhanced agreement between model and expert evaluations particularly on total scores.
Among the tested LLMs, Gemini-1.0 Pro demonstrated almost perfect agreement with expert reviewers. Meanwhile, models like GPT-4o and MultiVerse exhibited substantial agreement. Five additional models achieved moderate agreement, while others fell into the categories of poor to slight agreement. Interestingly, the analysis pointed out a moderate positive correlation between the size of the model and its performance on expert evaluations.
A key finding of the study is that while these models can effectively assess video quality, they tend to exhibit leniency in scoring. For example, LLMs had average scores ranging from 37.02 to 66.26 compared to an average of 32.8 offered by human experts. This discrepancy raises essential questions about how machine scoring aligns with traditional evaluation methodologies.
Moreover, the study underscores the varied performance across individual DISCERN questions. Some questions saw low inter-rater agreements, suggesting a need for further refinement in both LLM training and scoring methodology to ensure accurate assessments of health content. For instance, models often struggled with understanding the nuances of questions about clarity and treatment options, which impacted their ratings.
The implications of the research extend beyond academic interest; practical applications are evident. A proposed web application could leverage LLMs to help users navigate YouTube's vast collection of health-related videos by providing quality assessments and reliable content rankings based on overall scores generated by those models.
Ultimately, while LLMs present a promising avenue for mitigating the quality issue of health-related online videos, researchers emphasize caution. Ensuring consistent model performance across diverse topics and incorporating a more comprehensive set of evaluation criteria will be essential as the landscape of digital health information continues to evolve.
This pioneering study marks a significant step toward understanding the capabilities and limitations of AI in the health content evaluation realm. Future research could delve deeper into validating these models across various health fields and video types, expanding on the critical framework established in this examination.