A Novel Method For Efficiently Pre-training Language Models Introduced By Researchers Enhances Domain-Specific Performance.
A new subset selection method promises to improve the performance and reduce the computational costs associated with pre-training linguistic models across various domains.
The advancements of natural language processing (NLP) are being transformed by pre-trained language models (PLMs), heralding a new era of improvements in tasks ranging from sentiment analysis to question answering. However, these advancements come at a cost: the financial and computational resources required to fine-tune these plummeting algorithms can be astronomical. In face of such resource challenges, researchers have turned their attention to developing more efficient ways to utilize existing data. In this context, researchers from Korea have introduced AlignSet, an innovative method for selecting informative subsets from expansive domain datasets for efficient pre-training of language models.
The main goal of AlignSet is to facilitate faster learning of language models without the need to train on entire datasets, which are often unwieldy and consume significant computing power. This new approach allows for training a high-performing language model with significantly fewer data while still obtaining comparable—or even superior—results to those achieved through standard methods.
In their recent study, published on March 19, 2025, in the journal Scientific Reports, the authors demonstrate that AlignSet generates better subsets than traditional methods. Researchers compared this innovative algorithm against two existing methods, known as RandomSet and SuzukiSet, across various domains such as biomedical science, computer science, news reporting, and personal assessments.
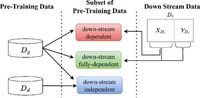
Prior research indicated that while precursor selection methods often relied heavily on the downstream dataset or tasks, AlignSet marks a departure by belonging to the down-stream independent group. This means it extracts subsets based solely on correlations from general pre-training datasets, addressing inherent limitations present in many subset selection techniques.
Economic imperatives drive the need for this type of efficiency in continuous pre-training (CPT) of domain-adaptive language models (LMs). For instance, the RoBERTa-large model typically requires a full day’s worth of processing time using 1,024 V100 GPUs for pre-training. AlignSet, however, streamlines this process, markedly reducing time and resource expenditures.
In testing, the proposed method outshined the competitors, outperforming RandomSet while still yielding a compelling performance in the news domain that was comparable to using a complete dataset. This scenario is pivotal for industries that increasingly demand rapid and efficient adaptation of language models to domain-specific tasks.
The researchers utilized the ALBERT model due to its computational efficiency and the experiments were conducted on four NVIDIA GeForce RTX 3090 GPUs, allowing for comprehensive testing across various cases.
Another significant finding indicated that while AlignSet takes longer than SuzukiSet, it is still more efficient than addressing the entire dataset, FullSet. This improvement proves critical, as extensive pre-training mandates extensive resources that small and medium-sized enterprises may lack.
To validate the performance of their method, researchers utilized multiple performance metrics: for models trained on subsets, they reported on the evaluation using macro-F1 and micro-F1 scores for classification tasks and Mean Absolute Error (MAE) for regression tasks, demonstrating the robust applications AlignSet supports.
The study concluded that AlignSet is not merely about finding effective subsets; it redefines how organizations can affordably and sustainably adapt language models to fit niche demands without compromising quality or performance.
In light of the growing discourse on the ethics of language model training—specifically regarding data privacy and usage—AlignSet's efficiency also inadvertently addresses broader societal questions by advocating for sensible use of available data. As organizations continue to face urgent cost-cutting pressures and higher standards for model performance, user-friendly methods such as AlignSet offer a pathway toward further advancements in natural language processing without sacrificing integrity.
This exciting development recognizes the urgent need to continuously optimize model performance while mitigating resource requirements. Researchers anticipate that through the iterative use of AlignSet, the quality of domain-adapted models will improve further, all while balancing the demands of economic efficiency and organizational effectiveness.
Ultimately, AlignSet is poised to provide researchers and businesses with new tools to navigate the complexities of modern natural language processing while enhancing the accessibility and capabilities of domain-specific language models.